
In the previous article, Web Scalability – Series / Part 1, we discussed the basics of web infrastructure scalability and how it can be used. Realizing the importance of fast paced apps with tons of data to process, we will cover this time, the basics of asynchronous processing.
What is Asynchronous Processing?
Imagine if you send a request to a webserver and then instead of waiting for its reply to comeback, you move on to do other stuff. It’s like multi-tasking in real life for us when we do multiple things and then react to them when they respond back. To quote the term,
Asynchronous processing, is about issuing requests that do not block your execution
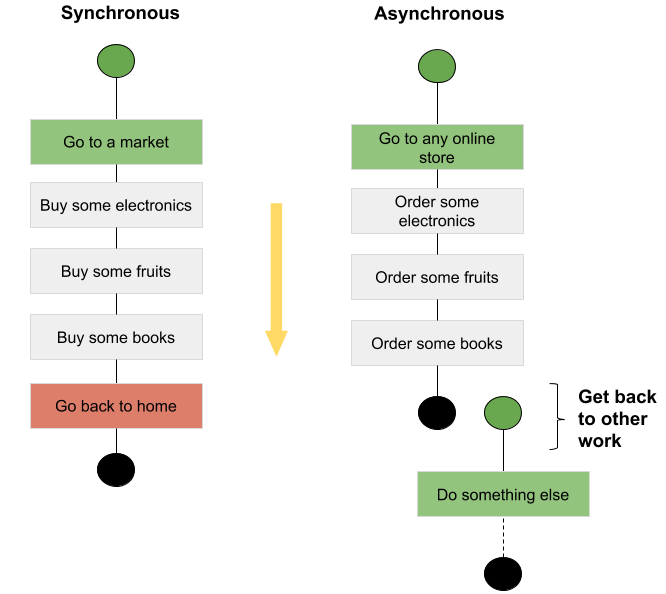
On the other hand synchronous processing is its opposite. A process that requests some service and waits until a response is received. Lets understand further using an analogy,
From the figure below, in case of Synchronous, you perform three independent ‘Buy …’ actions, one after another. When you order electronics, you pick some item, go to the cashier, pay the bill and continue buying rest of the stuff. Here, what you did is synchronous style shopping. In Asyncrhonous way, you buy something and move on to next buy action without waiting for it to be delivered at your home. You essentially took some actions and forgot about it, the system will take care of it once the response from the other party will arrive.
How can we achieve asynchronous processing?
You can achieve asynchronous processing using message queues that acts as a buffer to store your requests and dispatches them one by one in a first-come-first-serve basis. When we use message queues, it’s up to our application that how we can use them to achieve asynchronicity. Like you can consume the message by one thread, it will remain synchronous, but if you can have multiple threads consuming from the same queue, it will be emptied faster.
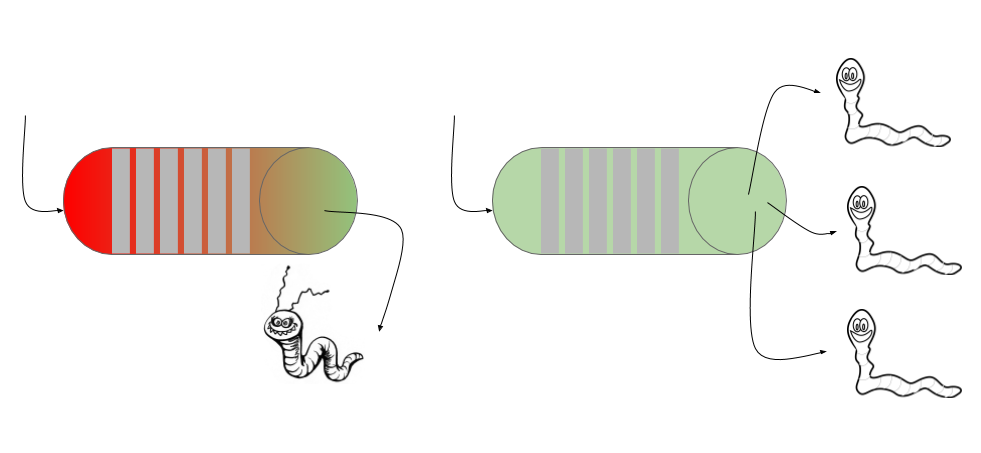
Messages in the message queue can be any textual information necessary to perform a particular task. Once messages arrive in the message queue, the producers of the message can forget about it and go on to process other work, while at the other end, when talking in terms of scalability, the consumer of those messages could be a separate process, running even on a remote server and even using a completely different technology stack. The way this type of processing has matured, its the best way to achieve flexibility and scalability at the same time.
The separation of producers and consumers using a queue gives us the benefit of nonblocking communication between producer and consumer
Now that they are operating separately, both producer and consumer can scale at their own requirements without affecting the overall performance. Consider a scenario when your server experiences traffic overload, the producer will emit tons of messages eventually filling the queue, while the consumers were only few. Here, you can scale up your consumers to fast process the queue to get undeterred performance result.
Here are some good implementations for message brokers that you can integrate with your application,
Kafka: Its an Apache based project, by LinkedIn, that gives high throughput, built-in partitioning, replication, and fault-tolerant message broker. The idea behind is to store data as flat files and the consumers can seek data using an offset. Learn more about Kafka here
ActiveMQ: Learn more about ActiveMQ here
RabbitMQ: by VMWare, Learn more about RabbitMQ here
Amazon MQ/SQS/SNS: these managed messaging services by Amazon are suitable for anyone from startups to enterprises. If you’re using messaging with existing applications, and want to move your messaging to the cloud quickly and easily, Amazon recommends using Amazon MQ. It will give you a lean start for your messaging requirements without any significant setup. Learn more about them here, Amazon MQ, Amazon SQS, & Amazon SNS
Popularity index of some messaging services
At times when applications are built to cater for millions of requests in a small amount of time, lightweight and parallel processing technologies is the way to go forward. The aggressive adoption of Kafka due to its performance has reached at the peak of popularity, running little ahead of RabbitMQ.
“Numbers represent search interest relative to the highest point on the chart for the given region and time. A value of 100 is the peak popularity for the term. A value of 50 means that the term is half as popular. A score of 0 means there was not enough data for this term.”
__
Next time, we will try to cover more about Data Indexing & Streaming. Suggestions are welcome in the comment section below.






