
Lets get right into managing high online traffic.
Managing High Online Traffic – TLDR;
In general, when companies – that run online services – create their systems to withstand high traffic but when it comes to occasions when traffic is expected to reach multiples of 10 times more traffic – that’s when you should plan in a different way.
Here is a quick list of things when preparing for planned high traffic:
- Predict the load on each system.
- Measure end-to-end latency for your scenarios. Across and within systems, availability zones, and resources.
- Stress test each system with ghost traffic.
- Code freeze, unless necessary. Open CI/CD only for hotfixes
- Ready your fallback or reserved systems in scenarios where there is a chance of front line services to fail. This also includes resource redundancy. Ready your database replicas.
- Traffic Routing, manage the load balancers so as to keep frequent type of traffic to bigger cluster of resources.
- Upfront data-migration in caches for read-heavy requests.
- Finetune the network bandwidth according to load estimates.
- Firewall rules for filtering out fake traffic in case of attack
- beef up the resources both horizontally and vertically like compute instances, databases, network bandwidth, and all that makes up your ecosystem.
- Have a disaster recovery plan, i.e. the steps to overcome failure. It’s better to have it automated then something which needs manual intervention.
- Monitoring. Create new and improved data pipelines to render realtime dashboards that can run stats across each vital system.
- Alerts. Create alerts based on monitoring thresholds. Setup oncall schedule for handling alerts. SMS/Email alerts. Consider yourself as a on-duty doctor during night and an accident patient arrives and you have no help and support from other doctors. You better be ready to take this responsibility or else divide the oncall support across team members.
- Document everything. Make sure your teams record everything. Be it system logs or decisions taken by supervisors. It’s important for incident retrospectives.
- Gather all the numbers, historical stats, and earlier pitfalls. This will help improve your preparation for the current and next iterations.
- Human communication is key. Everyone involved in operations, management, and key stakeholders should be on board and have medium of communications open all the time to reach out and make decisions. Print or circulate the mobile numbers of everyone involved with their respective responsibility.
Now, that you have read the quick list, we are only going to delve into a few things and skim over other things. For clarity, I have divided the process into 5 key phases.
1. Planning Phase
This is the first and most important phase of your preparation. Daraz did not handled 30M user visits during 11/11 sale without any serious preparation. This is where both management and engineering teams sit together, exchange data, talk numbers, and predict the upcoming traffic and then plan the course of actions. Lets see how it generally boils down to,
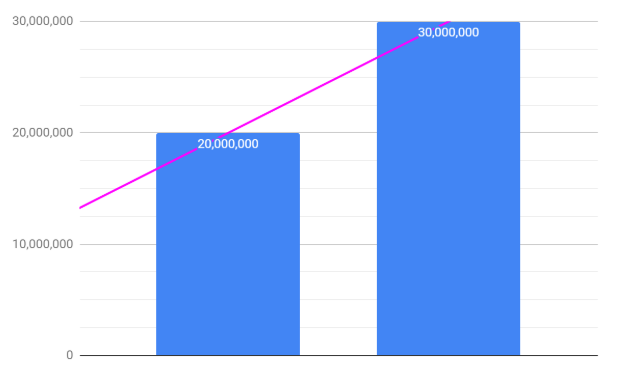
- Getting the statistics from historical high traffic events (like SinglesDay (11/11), blackfriday, amazon prime day, boxing day). The right numbers lead to predict the traffic growth which the teams must plan accordingly. Here is a yoy growth for daraz “user-visits” on singles day,
2018: 20Million
2019: 30Million
- Based on the predicted traffic, allocate responsibilities to individuals and teams – like swat teams for handling special cases. If you run out of human capacity, hire beforehand.
- Communicate with key stakeholders and document the contracts, if things go south. Imagine your marketplace fails for certain merchant, and that merchant loses tons of money, you want to onboard them before things go messy.
- Plan for budget allocation for increased capacity.
2. Preparation Phase
Beef up resources for high capacity
For high traffic online apps, cloud native solutions are generally adapted. Apart from commercial cloud offerings provided by Amazon, Google or Microsoft, which medium-to-large companies use, even bigger companies like Alibaba or Facebook, customize their own version of cloud to serve their purpose. One which make sures that several thousand microservices, databases, and networking switches can deliver their tasks without any interruption and all that in an automated way, where little-to-no manual intervention is required. Consider it like a war game of bots, where you have to make a strategy to control the enemy at different fronts and allocate resources to manage them, once you convey the plan to troops, they must deliver accordingly.
Now when it comes to capacity planning, there are several nuances to it, some related to network bandwidth requirements on several clusters to some database related where it’s important to make sure that there are enough read vs write DB nodes to handle the queries – measure RPM and QPS from stress testing results and beef up.
The aim is to deliver an end-to-end plan to handle any high peaks or continuous bursts of traffic where there is no weak link. But if you do have weak links like some 3rd party service is being called in the request flow, then you must have a backup plan ready like a timeout after some threshold and call the next service, even better if you adapt a circuit breaker pattern (hystrix or resilience 4j are good examples).
Monitoring
Monitoring is only good if its well thought through. Several systems emit events or logs which you can use to build dashboards on, be it system specific or business KPIs. But when it comes to engineering, you can go to minor details, bearing in mind the total cost analysis wrt business. You don’t want to ignore one tiny database being unresponsive for several minutes which potentially can be rejecting or cancelling orders of hefty amounts. Even dangerous if that service handles fraud patterns or may be doing compliance checks for financial transactions. Datadog, splunk are few good examples for monitoring
Alerts
Just remember – there is no way you can monitor all the metrics all the time, you must create automated alerts to ping you (disturb you in slang), configure your alerts to sms and email the relevant teams and stakeholders. Opsgenie is a good example.
3. Execution Phase
After all the planning and preparation, now it’s time to open the flood gates – start of the sale day – enjoy the symphony of high traffic converting traffic into millions in profits. Well, easier said than done. This is the critical mile of the whole exercise, as in Daraz, where they call it “all hands on desk” day. Even on nights, your duty is crucial like a medical doctor, you get the oncall phone to attend to any monitoring alerts.
4. Reporting
Compiling the report may feel boring, but its important to recollect various feedback reports from different concerned teams. You would most likely have digital dashboards from which you can export the summary, but spend more time to clearly and accurately report what you delivered. This will become useful for the next year’s planning.
5. Learning Phase
When things go south, there needs to be a retrospective to be done to make sure it never happens again. What happens in retrospective, you may ask? Well, you must submit a report to all stakeholders about what went wrong, how much losses it incurred, and how it was recovered (if ever). The natural next step is to create a backlog of tickets to improve the shortcomings highlighted in reporting.
Celebrate
Given that the whole preparation underwent successfully, it’s important to acknowledge the work done by all the teams involved. It goes a long way.
–
Open for feedback ofcoure! Share your thoughts, how do you manage in your organization – if you like it, plz share!







